Tuning Oracle Applications
The Three Most Popular Joins
by
Darryl B. Smith
11/19/97
There have been many cases when I have talked to people about explain plan and tkprof and wonder if they truly know all their options. With the newer versions of Oracle there have been dramatic improvements in join processing that many people may not know about. In the old days, the most efficient way to get 2 tables joined together, was by indexes. Now you have a few more options than that, and you may not even want indexes at all.
How does this statement make sense, everything I have been taught says, If you are joining 2 tables together then the most efficient way to join them is through an index. This is no longer true. With the use of sort/merges and hash joins you have a few more options. The problem is now defined by these questions. Should I use a nested loops join, a Sort/Merge join, or a Hash join? If I use one of these other methods, then will it really be faster? The last problem is, how do I get my query to work with them.
To begin with, Oracle has many ways to perform a join. The ones we are discussing here are the most conventional and apply in all situations. There are several other types introduced in Oracle 7.3 and Oracle8, however these are highly specialized and will not apply to most of your tuning opportunities.
The Nested Loops join process takes one of your tables and make it the driving table. A driving table will be the one where all other tables relate to it. It is typically the largest table or the table that will reduce the largest number of records in the query. For every record in the driving table, Oracle will go to the other tables to find data for it. This method will require indexes, because full table scans for every record in your driving table will be way to slow. If you don’t have an index and the driving table finds a record, it must finish scanning the entire table before knowing if all records have been retrieved
The Sort/Merge join process does a full table scan on all tables that it decides to do a sort merge with. Oracle will then take the records and sort them by the key from the where clause in your SQL statement. This join process will only work when you do an equi-join, or a join with an "=" in it. It won’t work if your trying to do any ranges as with an "in" or "between". Oracle will then take the 2 sorted sets of data and match them up to each other based on that key. This type of joining process will use sort areas. In order for this to be efficient, you should have enough sort area to hold all the information. If you don’t have enough sort area then Oracle will begin to swap the data out to your temporary tablespace causing your query to become very IO bound. To correct this you can increase the SORT_AREA_SIZE parameter in the init.ora file. You may have to contact your DBA and work with them to decide if it is appropriate to increase this size. To much sort area size could take away from the rest of the database processes. The sort area will use the part of the memory allocated for Oracle, leaving less room for your and other cache sizes. You may have to make a compromise with the sort area and accept some file IO.
The Hash join process does a full table scan on all tables that your query will use. Oracle will then take the records and break them up into sections. This join process will only work when you use an equal in your where clause. It won’t work if your trying to do any range scans, like in the sort/merge join process. Oracle will then take the 2 sets of data and decide which one will be loaded into memory and which one will do the scanning. Usually the table that easily fits into memory will be the table loaded as a hash table. This type of joining process will use twice the amount of your sort_area_size to perform this. In order for this to be efficient, you should have enough sort area to hold all the information. If you don’t have enough sort area then Oracle will begin to swap the data out to your temporary tablespace causing your query to become very IO bound. To correct this you increase the SORT_AREA_SIZE parameter in the init.ora file. Also, you can control the amount of hash area you use by a parameter called HASH_AREA_SIZE. You may have to contact your DBA and work with them to decide if it is appropriate to increase these sizes. To much sort or hash area will have the same effect as the increasing the sort are for the sort/merge.
The sort/merge and nested loop operations are the only 2 available when your optimization goal is rule. The hash join process is only available if you are in cost based. Later on in this article we will show you how to manipulate the query into each one of these modes.
In order to explain the effects of these joining processes we need to take a look at a couple of tables. By working with these 2 tables we can show you how to manipulate your queries, tables and indexes to force your query into one of these modes that will be most appropriate for you.
We will use these 2 tables:
CUSTOMER
| NAME | NULL? | TYPE | |
| ------------------------------- | -------- | ---- | |
| CUSTOMER_ID | NOT NULL | NUMBER(6) | |
| NAME | VARCHAR2(45) | ||
| ADDRESS | VARCHAR2(40) | ||
| CITY | VARCHAR2(30) | ||
| STATE | CHAR(2) | ||
| ZIP_CODE | VARCHAR2(9) | ||
| AREA_CODE | NUMBER(3) | ||
| PHONE_NUMBER | NUMBER(7) | ||
| SALESPERSON_ID | NUMBER(4) | ||
| CREDIT_LIMIT | NUMBER(9,2) | ||
| COMMENTS | LONG |
SALES_ORDER
Rows: 214200
Columns:
| NAME | NULL? | TYPE | |
| ------------------------------- | -------- | ---- | |
| ORDER_ID | NOT NULL | NUMBER(4) | |
| ORDER_DATE | DATE | ||
| CUSTOMER_ID | NUMBER(6) | ||
| SHIP_DATE | DATE | ||
| TOTAL | NUMBER(8,2) |
The common link between these 2 tables is customer_id. We will use this to create the following select statement:
select name,total
from sales_order ord,
customer cust
where ord.customer_id = cust.customer_id;
This select statement shows all customers and the total amount of their orders. This statement is retrieving data from each table. It is quite typical of a normal reporting select statement. It retrieves all rows from each table. Later on we will take a look at writing this query for a transaction based system which has a different set of rules than a batch processing or reporting query.
Nested Loops Join
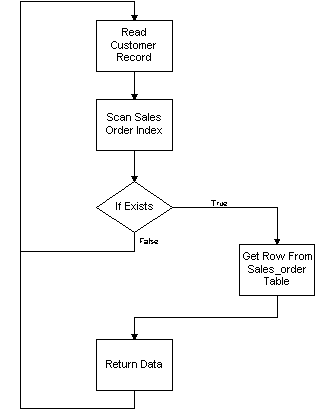
When using the nested loop join operation, we will see that the customer table becomes the "driving" or master table. The nested loop operation does a full table scan on the customer table to read each customer record. Oracle then takes each customer id and selects the total amount from the sales_order table based on that id. Typically there would be an index on the sales_order table based on customer_id to allow faster access to the actual data in the table.
When the select is issued, Oracle will read the first customer record, then see if that customer_id exists in the sales_order index. If the record existed in the index, then Oracle will go to the actual table to get the data from the total column. Oracle will access the table based on the rowid associated with that customer_id in the index. If no record exists then Oracle will read the next customer record and not return any data for that customer. If we had an outer join on the sales_order table then only customer data would be returned without the sales_order data. In our case, we only want the customers with orders, for display purposes.
When we look at the execution plan for this, we can see the path Oracle chose to take
Execution Plan
---------------------------------------------------
SELECT STATEMENT GOAL: RULE
NESTED LOOPS
TABLE ACCESS (FULL) OF 'CUSTOMER'
TABLE ACCESS (BY ROWID) OF 'SALES_ORDER'
INDEX (RANGE SCAN) OF 'SALES_ORDER_CUSTID' (NON-UNIQUE)
The only column used in our index is the customer_id and cannot be unique because of the fact that each customer can have many orders.
The following diagram gives you an idea what Oracle is trying to do with this query and how it is accessing the data.
Sort/Merge Join
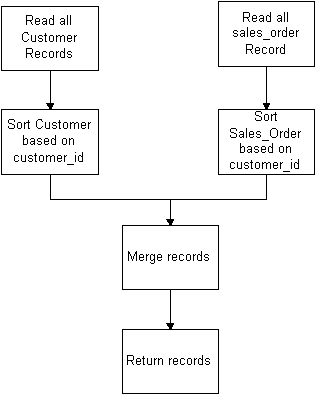
Now lets take a look at the sort/merge join operation. The sort/merge operation will do a full table scan on both tables and load them into a staging area to be sorted. If there is not enough sort area then Oracle will start swapping the data out to disk. Theoretically the sort/merge and hash join operations should be much faster than the nested loop operations when you are trying to join all data from both tables unless they become IO bound. If you find that the sort/merges and hash joins are actually slower, then you will want to investigate with your DBA to try and decide if you can tune the sort and hash area sizes to fit more data into them.
In a sort merge operation Oracle will basically follow these steps:
Hash Join
Hash joins are only used if you are using cost based optimization. You cannot use this through Rule based unless you force the cost based approach. You can force a cost based approach either by issuing an alter session statement
alter session set optimizer_goal = choose;
or by adding a hint to the SQLselect /*+ use_hash(cust) */
name,total
from sales_order ord,
customer cust
where ord.customer_id = cust.customer_id;
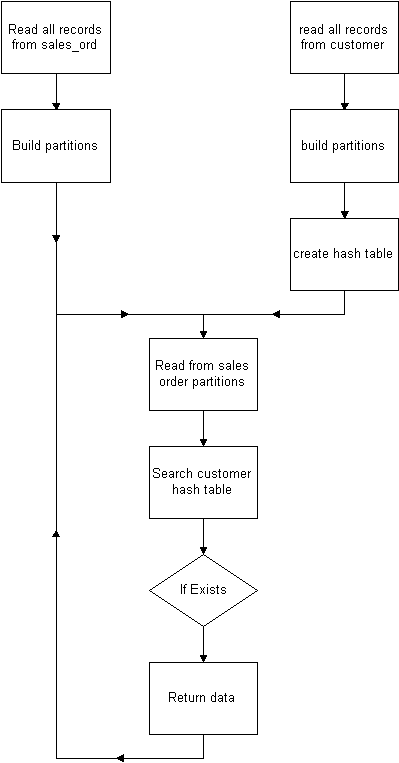
Oracle will then do a full table scan on each table, split it up into partitions of memory, build a hash table out of the smallest one and scan it with the records from the larger table. Because most of this is done in memory, hash joins can be twice as fast as a sort/merge join, which can be twice as fast as a nested loop join. The hash join operation will use twice as much space as the value specified in the sort_area_size value in the init.ora file. If this value is large you could have problems getting enough memory to do this operation. If there is not enough memory to hold all of the data then you can have problems with the system swapping the data out to disk.
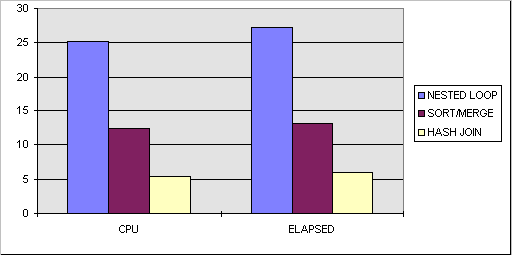
Here is a chart of how long each one of the joins took to join these 2 tables together and generate all of the output necessary for each one. As you can see the nested loop operation actually took the longest. This was the only operation that used an index. The sort/merge and hash join operations were done with no indexes on either table and they still performed much faster than the nested loop.
If we were to access this data for a single customer, we will find that the sort/merges and hash joins take longer. This is due to the fact that full table scans are performed. When you want quick access to single rows for transaction processing, then you will want to reduce the number of rows worked on as much as possible. When your indexes are set up properly and you have a very selective where clause, on your driving table, the nested loop operation will be the quickest. When using sort/merge and hash joins, a full table scan is performed and a filter is used to produce the rows you are looking for. The filter will choose the rows to display after the merge of the two tables. Therefore all processing takes place before any selection of rows from your result set.
What does all this mean?
You must know what options there are when you are trying to create a report or doing some other type of batch process that will join tables together. I have seen this useful for reporting purposes as well as for loading large amounts of data during a conversion or a data warehousing application where throughput is essential.
If you have any questions or comments, send them to webmaster@adsinc.com